지난 글 중 제가 구성한 Prometheus 기반 모니터링 시스템을 소개한 글이 있었습니다. 그 대상 시스템은 저희 연구실에서 운영 중인 IoT 기반 지진 감시 시스템입니다. 이번 글에서는 지진 감지 시스템에서 지진 발생 후 데이터 다운로드 ➝ 분석 ➝ 결과 알림 프로세스를 자동화한 시스템을 구축했던 내용을 소개하려 합니다.
Intro
동기
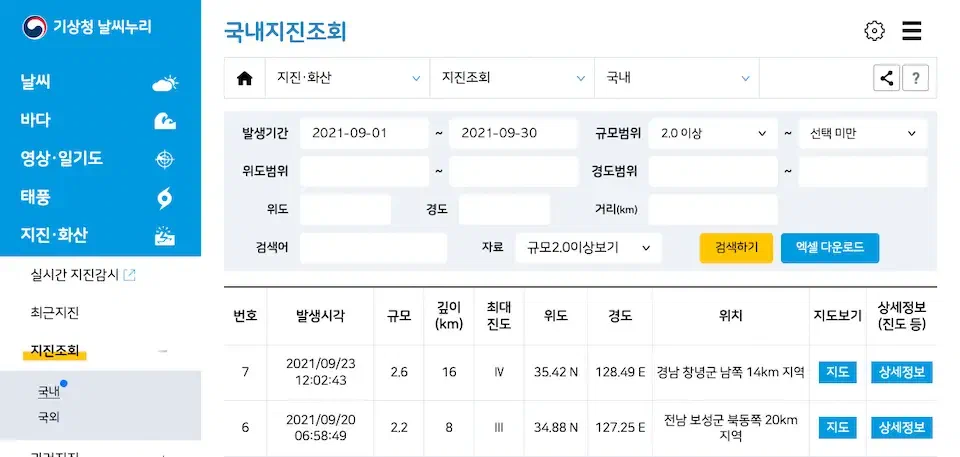
공부는 철이 들었을 때 하고, 자동화는 귀찮을 때…😂
2021년 9월, 추석을 맞아 본가에서 뒹굴거리던 중 LINE 재해 속보로 지진이 발생한 것을 알았습니다. 심지어 이 추석 연휴 동안 꽤 큰 (규모가 크지는 않지만 진도가 높아 사람들이 느꼈을만한) 지진이 두 번 발생했습니다.
이 때까지는 지진 발생 소식을 알게 되면 수동으로 주피터 스크립트를 실행해 데이터를 다운로드 받고, 수동으로 주피터 스크립트를 실행해 데이터를 분석하고, 수동으로 슬랙 메시지를 작성해 분석 결과를 공유했습니다. 하지만 추석 연휴에 누가 일을 하고 싶나요. 그래서 코딩을 했습니다??!
문제 해결 과정
거창하게 시스템이라고는 했지만, 과정과 목표는 간단합니다. 기존에 수동으로 실행하던 스크립트가 있기 때문에 이를 자동으로 실행하고, 실행이 끝나면 결과를 받아보는 과정입니다. 자동으로 실행하는 방법은 리눅스의 cron 기능을 활용했고, 결과는 저희 연구실에서 사용 중인 업무용 메신저인 슬랙으로 받아볼 수 있도록 Slack Incoming Webhook을 활용했습니다.
시스템 상세 구조
시스템 상세 구조를 도식화하면 다음과 같습니다.
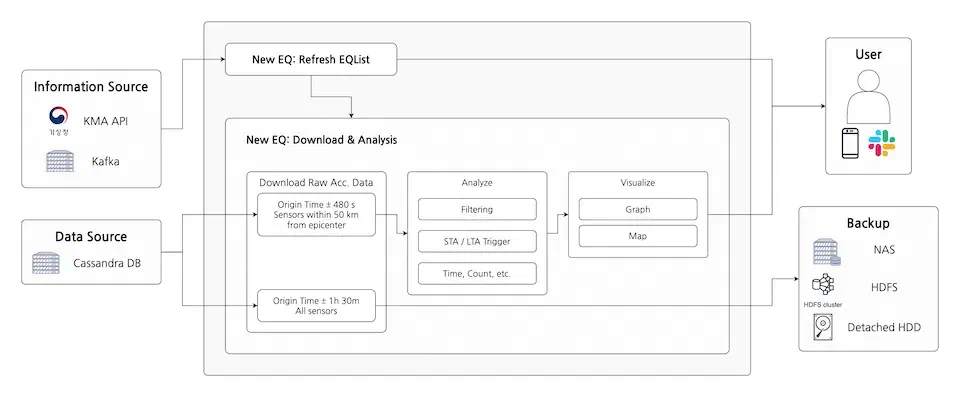
먼저, 기상청 지진정보 조회서비스 API로부터 지진 정보를 받아옵니다. API 파라미터 중 발표시각(From, To)은 일 단위까지 지원하고, 최대로 지난 3일까지의 데이터를 받을 수 있습니다. 때문에, 준 실시간으로 새 지진 정보를 받아오기 위해서 1분 마다 API를 호출하도록 했고, 이는 API에서 제한하는 일 최대 호출 건수 1만 건을 넘지 않습니다. 다만, 이러면 매 번 중복된 지진 정보를 받아올 수 있으므로 방금 받은 지진 정보를 이미 처리했는지 검사하는 과정이 필요합니다.
그 다음 새 지진 정보를 사용해 데이터를 다운로드 받고, 여러 분석 과정을 거칩니다. 센서로부터 수집된 데이터는 잡음이 섞여있을 수 있기 때문에 필터링 과정을 거치고, STA/LTA (Short Term Average / Long Term Average)라는 방식을 사용하여 센서가 트리거 되는 시점을 파악합니다. 이 작업은 지진 데이터 분석을 위한 파이썬 라이브러리인 ObsPy를 활용했습니다.
마지막으로 사용자가 이해하기 쉽도록 분석 결과를 그래프나 지도 이미지로 시각화하는 과정을 거칩니다. 이 결과물은 슬랙 알림을 통해 사용자에게 전달되고, 내부에서는 여러 곳으로 분산 백업을 진행합니다.
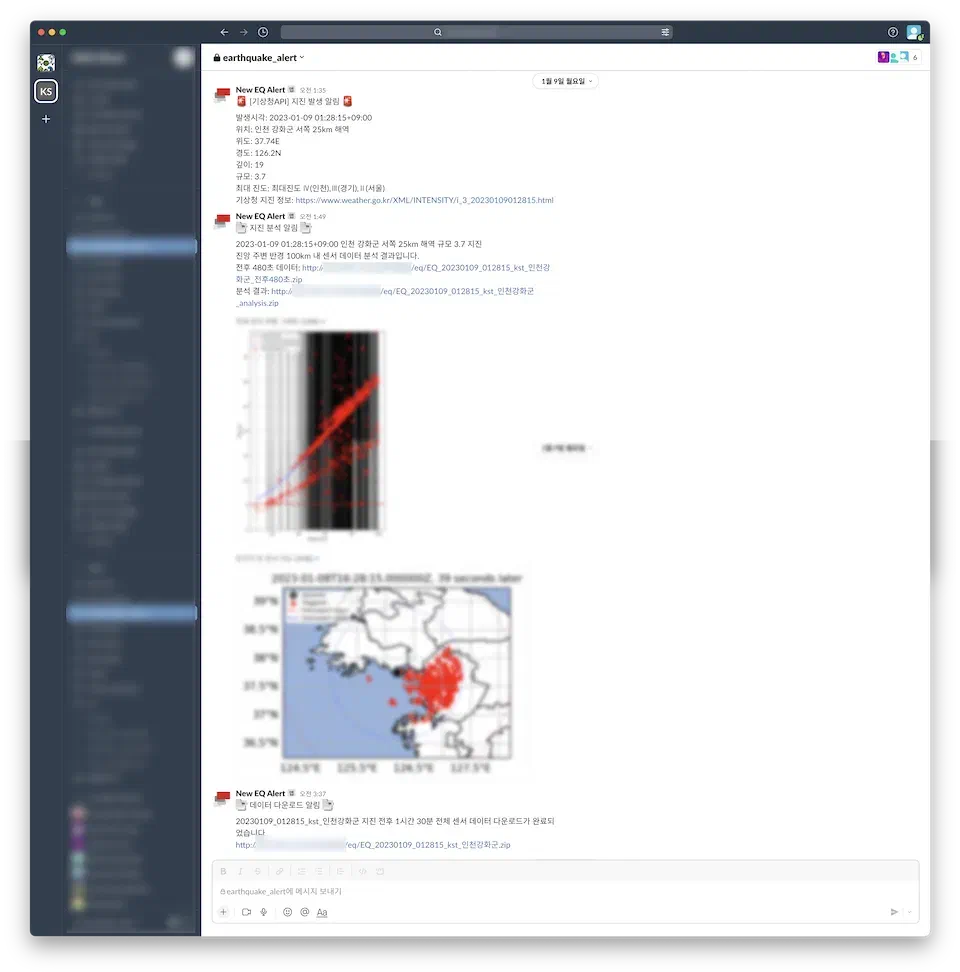
가장 초기 단계에는 지진이 발생했는지 기상청 국내 지진 조회 사이트에서 직접 들어가서 수동으로 확인하거나 뉴스에 의존했기 때문에 결과를 보는 것이 매우 느렸습니다. 사후 분석이었죠. 하지만 이 시스템을 구축하고 나서는 (제가 귀찮게 일을 안 해도 됐을 뿐만 아니라) 지진 발생 후 약 1시간 후에 자동으로 분석 결과를 받아볼 수 있었습니다.
개선 사항
아무리 연구, 개발 중인 시스템이고, 위 내용이 사후분석이기도 하고, 수동 분석보다는 월등히 빠르긴 하지만 1시간은 조금 늦은 것도 사실입니다. 이 후 이를 해결하기 위한 여러 번의 업데이트와 버그 수정이 있었습니다.
첫 번째로는 전체 센서 데이터 다운로드가 시간이 꽤 소요된다는 점을 발견했습니다. 하지만 지진파는 거리가 멀어질수록 약해지므로 만약 인천에서 지진이 발생했다면 굳이 대전이나 부산 센서의 데이터를 다운로드 받을 필요는 없습니다. 그러므로 진앙 주변 센서에 대해 지진 발생 후 몇 분 정도의 데이터만 다운로드해 분석하도록 변경했습니다. 추후 연구 목적으로 사용 가능하도록 전체 센서 데이터 다운로드 작업은 분리했습니다.
두 번째로는 이 스크립트가 사후 분석 스크립트이다 보니 데이터를 카프카 메시지 큐에서 바로 받아서 쓰는게 아니라 DB를 한 번 거치게 됩니다. 그런데 DB에 데이터를 넣는 덤프 작업의 주기가 이전엔 1시간 간격이어서 지진이 발생하더라도 데이터 다운로드를 위해 한참 기다려야 되는 문제가 있었습니다. 이 정책은 추후에 개선되어 5분 주기로 변경되었고, 이 정책 개선 작업을 제가 한 것은 아니지만 주기가 변경되었다는 내용을 전달 받은 후 저는 제 작업이 실행되는 cron 주기를 더 줄여서 결과 더 빨리 볼 수 있도록 개선했습니다.
이를 통해 현재는 지진 발생 시각을 기준으로 약 10분 정도 후 슬랙으로 분석 내용을 받아보고 있습니다.
마치며
이 시스템은 (이렇게 오래 쓰게 될 줄은 몰랐지만) 지금까지도 잘 쓰고 있습니다. 이 후 약간의 업데이트와 몇 번의 버그 수정을 거치긴 했지만 기본적으로 스크립트를 cron으로 실행하는 것은 그대로입니다.
그래서 최근 오버홀 작업을 진행하고 있습니다. 분석이나 알림 로직의 경우에는 어느 정도 완성된 버전이므로 그대로 사용하되, cron에 의존하는 스크립트 실행이 아니라 주기적으로 Job을 실행 가능한 프로그램 형태로 변경 중입니다. 또한 이를 Prometheus client와 연동하여 실행 메트릭과 로그를 기존에 구축해 둔 모니터링 대시보드에서 볼 수 있도록 포함하는 작업을 진행 중입니다.
또한, 그래프와 지도 이미지를 생성하는 작업도 시간이 많이 소요되고 있어서 추가적인 시간 단축을 위해 병렬로 이미지를 생성하도록 수정을 진행 중입니다. 일반적으로 병렬 작업을 떠올리면 멀티 스레딩을 생각하겠지만 파이썬에서는 GIL(Global Interpreter Lock) 때문에 멀티 스레딩으로는 성능 향상을 기대하기가 어렵습니다. 그래서 멀티 프로세스를 활용하는 수정도 병행하고 있습니다.
추석 연휴에 반 귀찮음 반 짜증으로 시작했던 작업이었고, 몇 번의 당황스러운 일도 있었지만 이 시스템을 만들고 버그 픽스를 하면서 덕분에 파이썬에 많이 익숙해졌던 것 같습니다.
GIL이나 멀티 프로세스 관련 내용은 추후 포스팅을 통해 더 자세한 설명과 함께 돌아오겠습니다.
Comments