지난 글에서는 제가 구성한 Prometheus 기반 모니터링에 대해 간단하게 소개를 했습니다. 이번 글은 실습을 해보겠습니다.
준비사항
| 버전 | 비고 | |
|---|---|---|
| Docker | ^20.10.2 | Windows, Mac 사용자는 Docker Desktop 버전으로 설치해야 합니다. |
| Docker compose | ^1.27.4 | Docker Desktop을 설치하면 자동으로 설치됩니다. |
Exporter 실행
Prometheus는 이전 글에서 언급했듯 Pull 방식을 사용합니다. 그러므로 모니터링 대상 컴퓨터에 정보를 제공하는 Exporter가 설치되어 있어야 합니다. 여기서는 Unix 기반 컴퓨터에서 하드웨어와 OS 메트릭을 제공하는 Node Exporter를 도커를 이용해 설치해 보겠습니다.
1docker run -d \
2 --restart "unless-stopped" \
3 --net="host" \
4 --pid="host" \
5 -v "/:/host:ro,rslave" \
6 --name "node_exporter" \
7 prom/node-exporter:latest \
8 --path.rootfs=/host
이제 localhost:9100/metrics로 접속하면 많은 메트릭 데이터를 볼 수 있습니다.
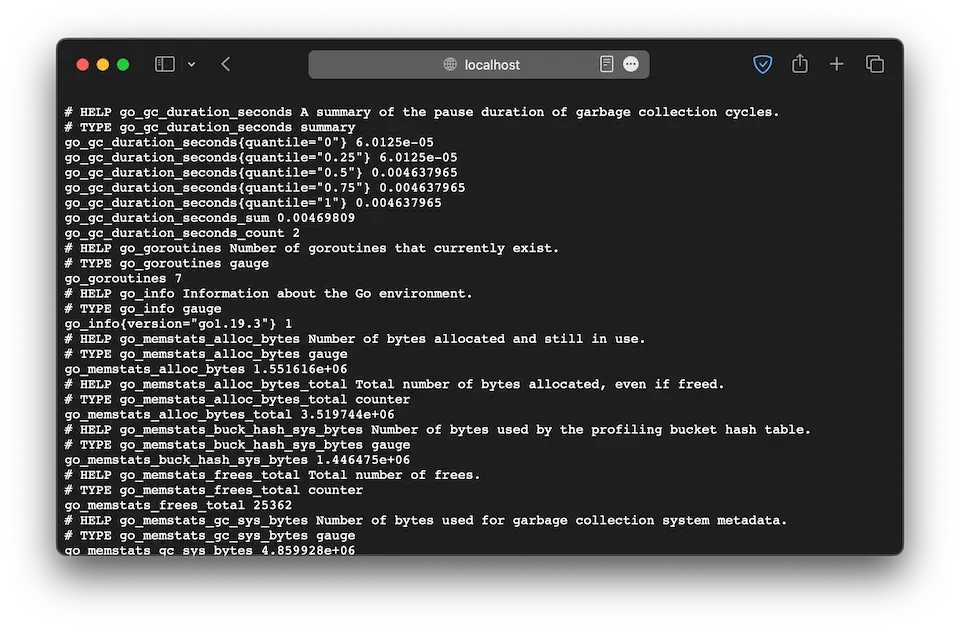
Target 등록
Prometheus가 Pull 방식으로 정보를 가져올 모니터링 대상을 지정해줍니다. 여기서는 Prometheus 서버 자체와 위에서 등록한 Exporter 정보를 가져오도록 설정하겠습니다.
1// ./config/prometheus.yml
2global:
3 scrape_interval: 30s
4
5rule_files:
6 - rules.yml
7
8scrape_configs:
9 - job_name: my_server
10 scrape_interval: 10s
11 static_configs:
12 - targets:
13 - prometheus:9090
14 - host.docker.internal:9100
- scrape_interval: 정보를 가져올 주기를 설정합니다. 기본값은 1분입니다.
- rule_files: 모니터링 규칙을 지정할 yaml 파일 목록입니다.
- scrape_configs: 이 부분이 모니터링 대상에 대한 세부 설정을 하는 부분입니다.
- job_name: 모니터링 대상의 닉네임입니다.
- scrape_interval: global 설정을 이렇게 각 타겟 별로 덮어쓸 수도 있습니다.
- static_configs: 실제 모니터링 대상을 지정하는 부분입니다.
- host.docker.internal: 아까 Node Exporter를 띄울 때 localhost로 접속을 했습니다. 하지만 여기서
localhost를 쓰면 우리가 생각하는내 컴퓨터:9100이 아니라prometheus컨테이너:9100으로 접속하게 되고, 당연하게도 아무 메트릭도 못 가져옵니다. 그래서내 컴퓨터로 접속하도록 설정해줍니다. 다른 컴퓨터라면 공유기 내부망 IP나 공인 IP를 사용하시면 됩니다. - 더 자세한 설명은 공식 문서를 참고해주세요.
Rule 등록
1// ./config/rules.yml
2groups:
3 - name: my_server_up
4 rules:
5 - alert: InstanceDown
6 expr: up{job="my_server"} == 0
7 for: 30m
8 annotations:
9 title: "Instance {{ $labels.instance }} down"
10 description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 30 minute."
11 labels:
12 severity: "critical"
- name: 큰 그룹의 이름입니다. 아래 rules에서 여러 개의 규칙을 정의할 수 있습니다.
- alert: 알림을 발송할 ‘규칙 이름’입니다.
- expr: PromQL로 작성한 규칙입니다.
- for: 규칙이 이 시간 이상 참일 때 알림을 발송합니다. 위 예시에서는 모니터링 대상이 응답을 할 때는 up 쿼리의 결과가 0이 아닐 것입니다. 그러므로 서버에 어떤 문제가 있어서 up 쿼리의 결과가 0인 상황이 30분 이상이면 알림을 보냅니다.
- annotations: 알림 메시지 템플릿입니다.
Prometheus 실행
1// docker-compose.yml
2version: "3.9"
3
4services:
5 prometheus:
6 image: prom/prometheus
7 ports:
8 - 9090:9090
9 volumes:
10 - ./config/prometheus.yml:/etc/prometheus/prometheus.yml
11 - ./config/rules.yml:/etc/prometheus/rules.yml
12 - prom_data:/prometheus
13 restart: unless-stopped
14
15volumes:
16 prom_data:
- image: 도커 허브에 있는 prom/prometheus 이미지를 사용합니다.
- ports: prometheus 웹ui에 접속하기 위해 포트를 노출해줍니다.
- volumes: 위에서 만든 설정 파일을 컨테이너 안으로 연결해서 사용합니다. 또한, prom_data라는 볼륨을 만들어 사용합니다. 이렇게 하면 컨테이너를 삭제하더라도 데이터는 남길 수 있습니다.
설정을 다 했으니 실행을 해봅니다.
1> docker compose up -d; docker compose logs -f --tail=1000
2
3[+] Running 13/13
4 ✔ prometheus 12 layers [⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿⣿] 0B/0B Pulled 19.5s
5 ✔ 9836d7c30387 Pull complete 1.4s
6# ...
7[+] Running 3/3
8 ✔ Network prom-grafana-monitoring_default Created 0.0s
9 ✔ Volume "prom-grafana-monitoring_prom_data" Created 0.0s
10 ✔ Container prom-grafana-monitoring-prometheus-1 Started 0.7s
11prom-grafana-monitoring-prometheus-1 | ts=2023-04-23T08:14:10.402Z caller=main.go:520 level=info msg="No time or size retention was set so using the default time retention" duration=15d
12prom-grafana-monitoring-prometheus-1 | ts=2023-04-23T08:14:10.402Z caller=main.go:564 level=info msg="Starting Prometheus Server" mode=server version="(version=2.43.0, branch=HEAD, revision=edfc3bcd025dd6fe296c167a14a216cab1e552ee)"
13# ...
14prom-grafana-monitoring-prometheus-1 | ts=2023-04-23T08:14:10.406Z caller=tls_config.go:232 level=info component=web msg="Listening on" address=[::]:9090
15# ...
16prom-grafana-monitoring-prometheus-1 | ts=2023-04-23T08:14:10.412Z caller=main.go:1246 level=info msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=1.648806ms db_storage=4µs remote_storage=1.125µs web_handler=458ns query_engine=709ns scrape=265.62µs scrape_sd=26.249µs notify=750ns notify_sd=1.25µs rules=800.82µs tracing=18.916µs
17# ...
18prom-grafana-monitoring-prometheus-1 | ts=2023-04-23T08:14:10.412Z caller=manager.go:974 level=info component="rule manager" msg="Starting rule manager..."
그럼 이제 localhost:9090/targets, localhost:9090/rules로 접속해봅시다.
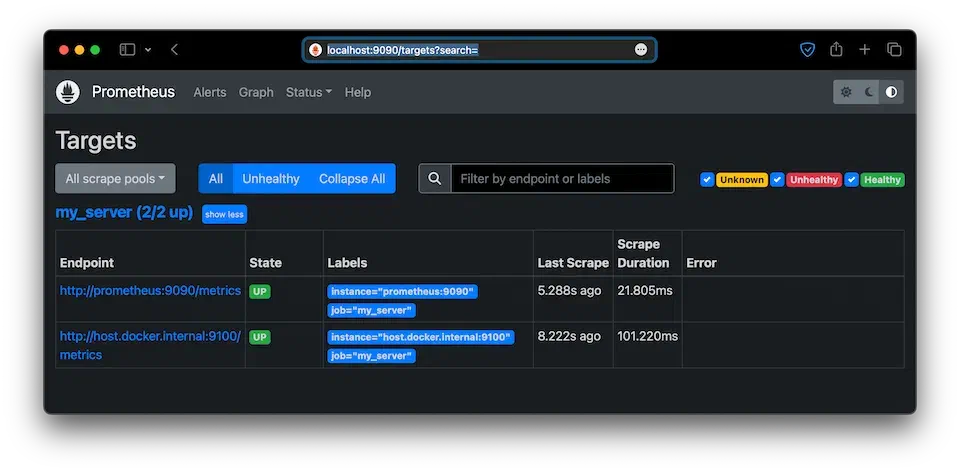
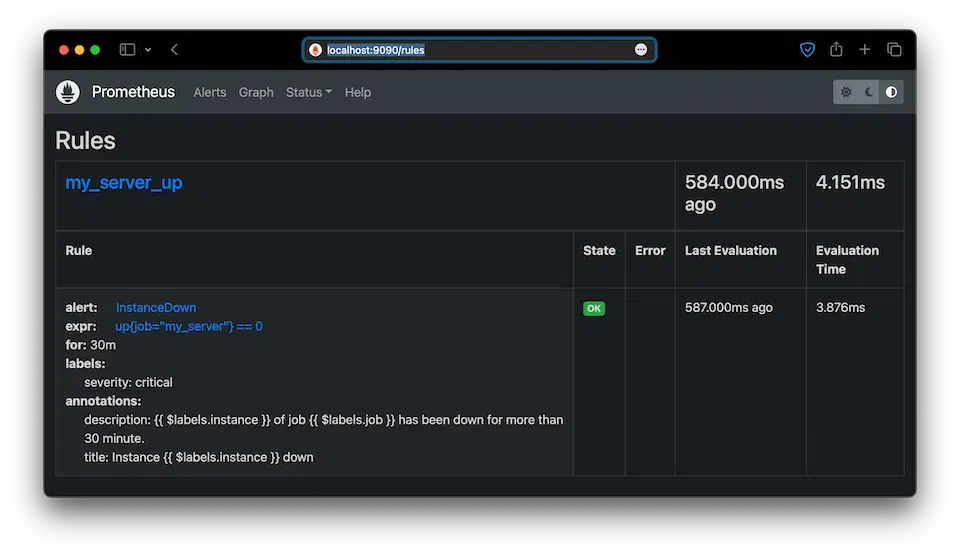
우리가 지정했던 대상과 규칙이 잘 적용된 것을 확인할 수 있습니다.
대상 시스템을 여러 개 등록하고 싶다면 prometheus.yml에서 targets, job을 여러 개 등록하고, rules.yml 파일에서 원하는 쿼리를 추가해주면 됩니다.
이번 글에서 사용된 코드는 깃허브에서 확인할 수 있습니다.
Comments