저는 지난 2021년 여름부터 Prometheus를 사용해 모니터링 시스템을 구성하고 사용 중입니다. 이번 글에서는 Prometheus를 이용한 모니터링에 대한 간단한 소개와 활용 예시를 보여드리려 합니다.
Intro
시스템 구성 동기
모니터링과 로그, 메트릭 분석, 검색 시스템으로는 유명한 ELK(Elasticsearch + Logstash + Kibana) 스택이 있습니다. 하지만 ELK 스택은 그 대단한 성능만큼 굉장히 크고 복잡한 시스템입니다. 제가 이 모니터링 시스템을 구성할 때는 타겟 시스템도 한창 개발 중이던 상태여서 모니터링 시스템이 제대로 갖춰지지 않은 상태였습니다. 때문에 시스템의 문제 상황을 분석하는 것보다 문제가 발생했다는 것을 인지하는 것 먼저 차근차근 진행할 필요가 있었습니다. 그래서 ELK 스택보다 비교적 단순하지만 성능은 충분한 Prometheus를 이용해 모니터링을 구성했습니다.
Prometheus란?
Prometheus는 숫자 형태의 시계열 메트릭 데이터를 위한 오픈소스 모니터링 & 알림 시스템입니다1. Prometheus를 활용한 모니터링 시스템은 다음 그림과 같이 구성됩니다.

- 기본적으로는 왼쪽 아래 Targets가 있고, 이 타겟 서버에 Exporter라는 것을 설치합니다.
- Prometheus는 타겟의 Exporter가 제공하는 정보를 Prometheus Server가 가져가는(Pull) 방식을 취하고 있습니다. 이는 ELK 스택에서 사용하는 Push 방식과 다르게 동작합니다.
- Push, Pull 방식의 차이가 있지만2 상황에 따라 적절히 선택하면 되는 수준이고
- 제가 모니터링하는 대상 시스템의 규모가 크지 않은 점, 주기적으로 서비스의 생존이 확인되지 않는 경우를 빠르게 아는 것이 중요하다는 점에서 Pull 방식의 Prometheus도 충분히 적합하다고 생각됩니다.
- Prometheus가 수집기와 TSDB의 역할을 한다면 Grafana는 이들이 모은 데이터를 보여주는 Visualizer, Dashboard로, 이 역시 오픈소스입니다.
- 수집된 메트릭 데이터로 Rule 기반의 이상탐지를 수행할 수 있습니다. 만약 규칙에 어긋나는 상황이 발생할 경우 Alertmanager를 통해 상황 발생 소식을 전파할 수 있습니다.
시스템 구성
다음 그림은 현재 제가 구성한 모니터링 시스템을 도식화 한 것으로, 기본적인 구성은 Prometheus 공식 아키텍처와 비슷합니다.
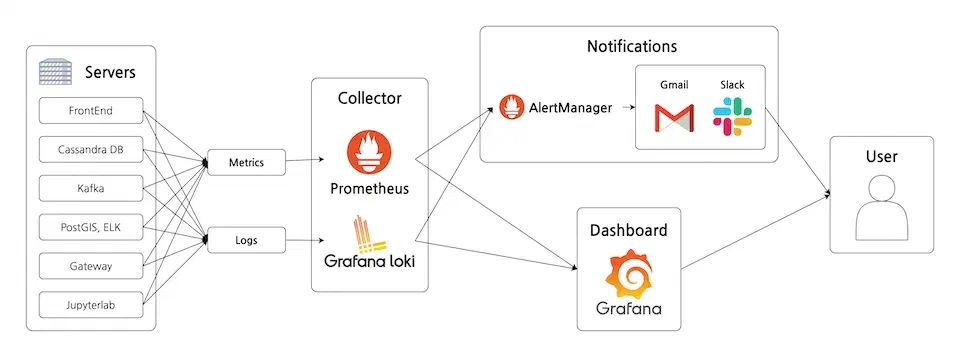
제가 모니터링 하고 있는 타겟 시스템은 약 5천여 대의 IoT 센서로부터 실시간으로 지반의 흔들림 데이터를 수집하고 처리하여 지진을 감시하며, 이는 재난 대응을 위한 중요한 시스템이기 때문에 모니터링 시스템을 구성하여 대상 시스템의 이상 징후를 감시하고 있습니다34. 그리고 시스템에서 동작하는 여러 서버 중 문제가 발생하면 메일 또는 슬랙 알림을 받을 수 있게 구성했습니다.
본 모니터링 시스템에는 위에서 본 그림과 다르게 Grafana Loki라는 서비스가 있습니다. Loki는 Prometheus와 비슷하지만 Prometheus는 메트릭 데이터를, Loki는 로그 데이터를 담당합니다.
모니터링 운영
Prometheus는 PromQL이라는 전용 쿼리 언어를 사용하여 수집한 메트릭 데이터를 볼 수 있습니다. 또한, 이 쿼리 언어를 사용해 Rule을 만들어 시스템의 이상 상황을 탐지할 수 있습니다. 가장 기본적으로는 up() 쿼리를 사용하여 타겟 서버들이 정상적으로 연결되어 있는지(Prometheus 서버가 타겟 서버의 Exporter로부터 데이터를 pull할 수 있는지)를 파악하고, 일정 시간 이상 연결이 안 된 경우 알림을 보내는 파이프라인을 구성할 수 있습니다.
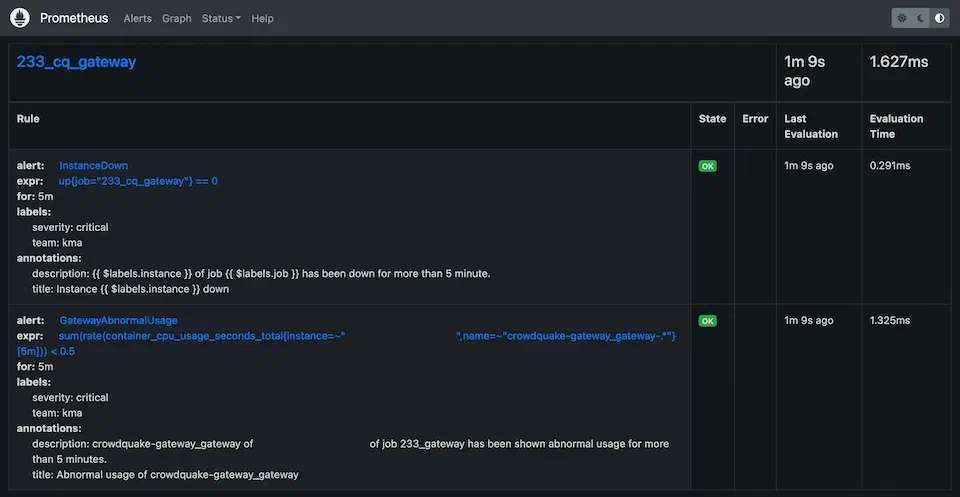
여기서 잠깐, 모니터링 시스템에서 이상 징후를 탐지하는 데는 크게 Rule 기반과 최근에 뜨는 인공지능/딥러닝 기반으로 나누어 볼 수 있습니다. Rule 기반 모니터링은 정해진 규칙에 맞는지 아닌지만 판별하면 된다는 장점이 있습니다. 몇 년 전부터 인공지능, 딥러닝 유행이 다시 오면서 이를 사용한 이상 탐지 모니터링 시스템도 많이 나오고 있지만 모델의 크기가 커지면 실시간으로 운영하기 어려워질 수 있습니다. 하지만 Rule 기반은 상대적으로 덜 무겁죠.
그러나 Rule 기반 모니터링은 운영자가 시스템에 대해서 잘 알아야 한다는 어려움이 있습니다. 인공지능 기반 모니터링은 ‘학습만 잘 시켜주면 알아서 한다’는 것이 장점이기도 하죠. 그래서 이 때는 제가 대상 시스템에 대해서도 잘 모를 때였고, 모니터링도 처음 시도하던 때라 up 규칙만 추가해두고, 한 달 정도는 모니터에 계속 Grafana 대시보드를 띄워둔 채 수시로 지켜봤던 기억이 납니다. Prometheus 책과 여러 블로그를 보며 셋업은 해뒀지만 대상 시스템에 대해서 잘 모르던 시기였거든요.
이 때 대상 시스템을 지켜보면서 알게 된 사실은 다음과 같습니다.
- 앞서 말했던 5천여 대의 센서가 10대의 게이트웨이를 거쳐 들어옵니다. 이 때 센서 또는 네트워크에 어떠한 문제가 생겨 일부 또는 전부가 안 들어오게 되면 게이트웨이의 사용량(부하)가 낮아집니다.
- 그 다음으로 게이트웨이에 들어오는 데이터가 적거나 없으니 DB에 저장되는 데이터도 줄어듭니다. 그러므로 DB 사용량도 줄어들게 됩니다.
그리고 추후 이들도 Rule으로 추가하였습니다.
사실 이 내용은 조금 당연한 것일 수 있지만, 이 때의 경험 상으로는 대상 시스템의 규모가 큰 것에 비해 비교적 서비스 간 복잡도는 크지 않아서 서비스에서 문제가 일어나는 일은 거의 없었습니다. 그것보다 외부적인 문제(학교 정보화 본부의 네트워크 장비 교체, 연구실 건물 정전 등)가 더 컸기 때문에 감시 규칙을 많이 추가하지는 않았고, 대신 외부 장비를 활용한 이중화나 UPS 쪽을 더 고민했던 기억이 납니다.
알림 예시
시스템 연결 상태 모니터링
up 규칙으로 알림 데모를 하는 것은 쉽습니다. Exporter 프로세스를 종료하면 되거든요. 그러면 정해진 시간이 지나고 Prometheus에서 Alertmanager를 통해 알림을 보냅니다.
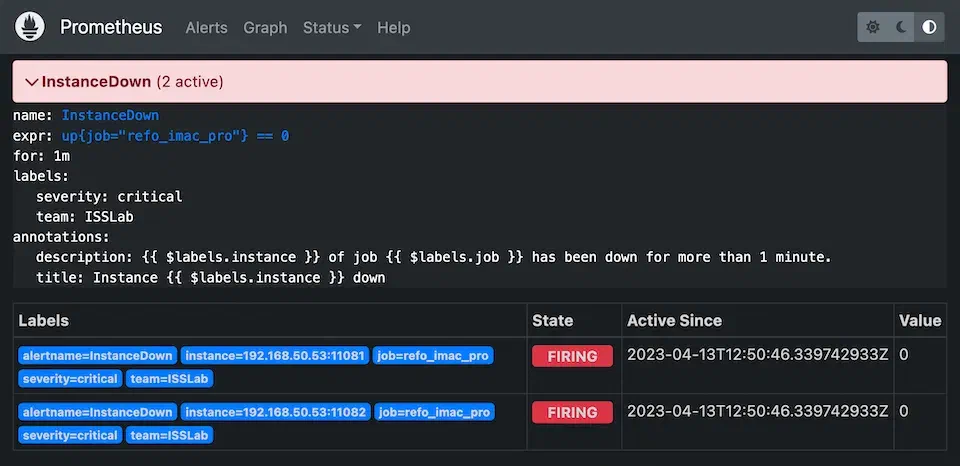
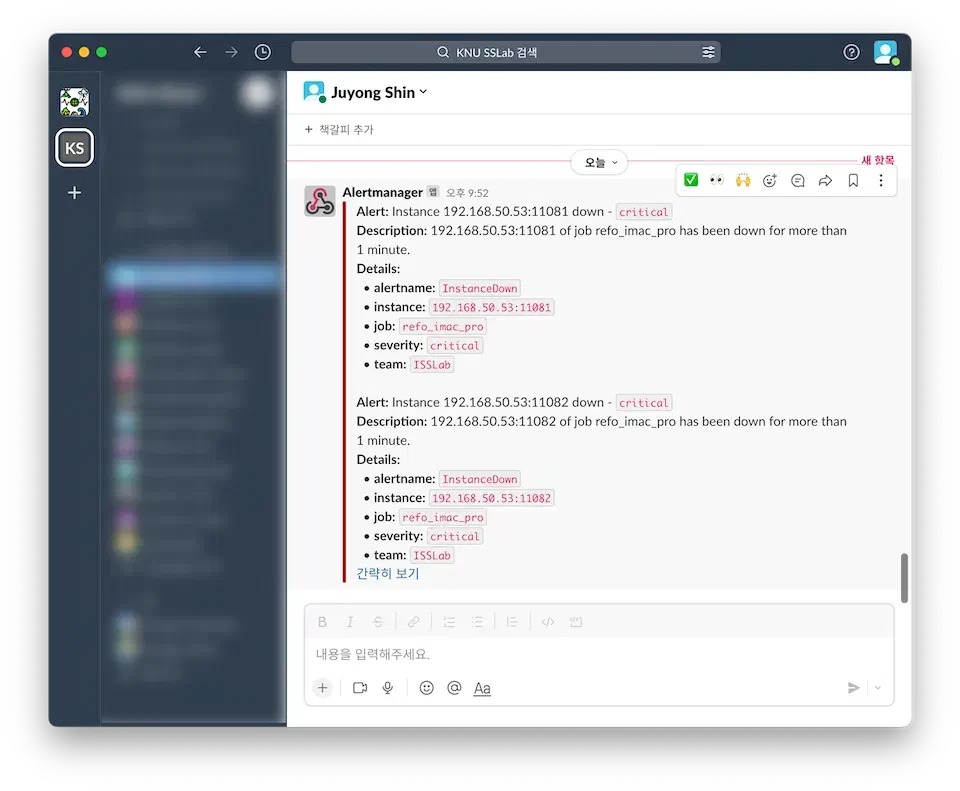
만약 시스템이 복구됐을 때도 알림을 받고싶다면 resolve_timeout 옵션을 사용하면 문제가 해결 됐을 때도 알림을 보내도록 할 수 있습니다.
시스템 자원 사용량 모니터링
한동안 Grafana 대시보드를 수동으로 계속 보던 중 평소와는 다른 패턴을 발견했습니다.
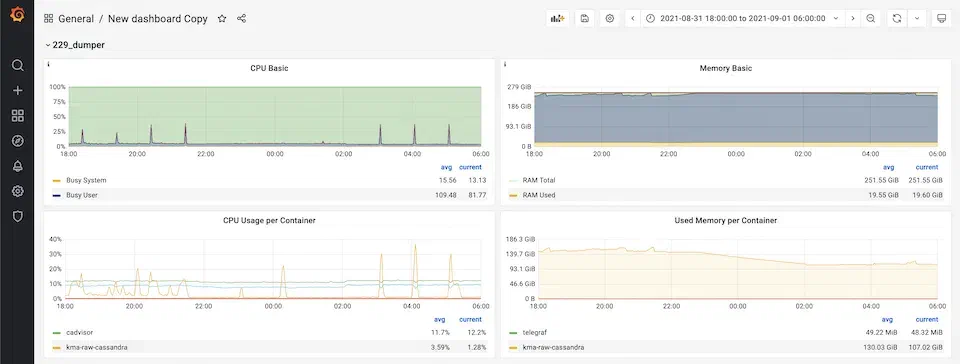
이 서버에는 Cassandra DB가 동작하고 있었고, 1시간마다 DB로 데이터를 넣는 작업이 수행되었습니다. 그래서 CPU 사용량을 보면 1시간 간격으로 부하가 걸려 피크를 보입니다. 그런데 왼쪽 아래 컨테이너별 CPU 사용량 그래프를 보면 CPU 사용량이 불규칙하다가 22시부터는 거의 0%에 가깝게 떨어지는 모습을 보였습니다. 분명 사람이 봤을 때는 이상한 상황이지만, 위에서 추가했던 up 규칙으로는 계속 데이터가 들어오는 상태였기 때문에 탐지할 수 없고 알림도 발송되지 않았습니다.
이 문제를 해결하기 위해 CPU 사용량 모니터링을 위한 규칙도 추가했습니다. 하지만 피크를 어떻게 규칙으로 표현할지가 문제였습니다. 그래서 선택한 방법으로는 시스템 구성 단락에서 잠깐 소개했지만 “뭔가 문제가 생겨 센서 데이터가 안 들어오면 ➝ 처리할 데이터가 없으니 게이트웨이에 부하가 안 걸릴 것이고 ➝ DB에 저장할 데이터도 없을 것이므로 ➝ DB도 사용이 안 될 것이다” 라고 생각했습니다. 그래서 게이트웨이와 DB의 CPU 사용률을 탐지하는 규칙을 추가했습니다.
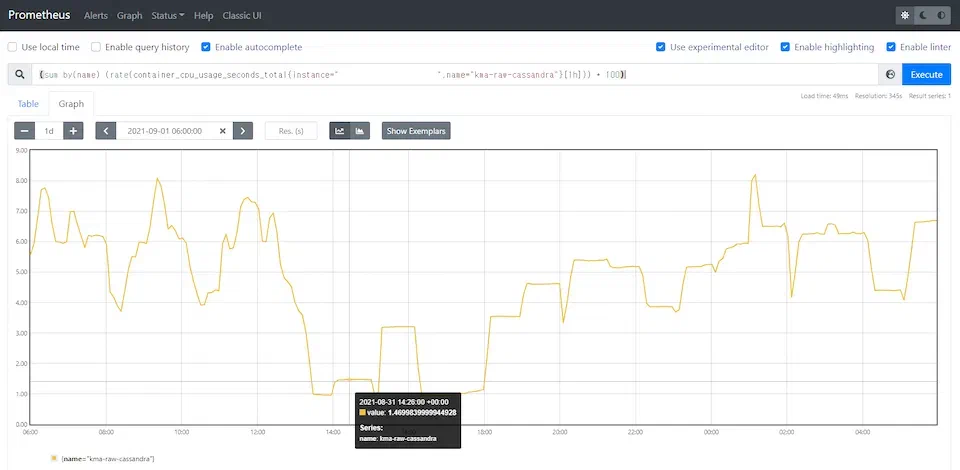
이 쿼리는 Cadvisor에서 제공하는 container_cpu_usage_seconds_total 메트릭을 활용하였고, 1시간 동안의 메트릭 데이터를 가져와서, rate 함수로 집계하여 1시간 길이의 데이터 배열을 1개의 벡터 값으로 만들어줍니다. * 100은 값이 너무 작아서 scale 해준 것이고, sum by (name)은 결과값을 그룹별 집계하는 코드인데 이 경우에는 제가 필요한 컨테이너 name을 명시해줬으므로 쓸모 없는 중복 쿼리가 되겠네요..
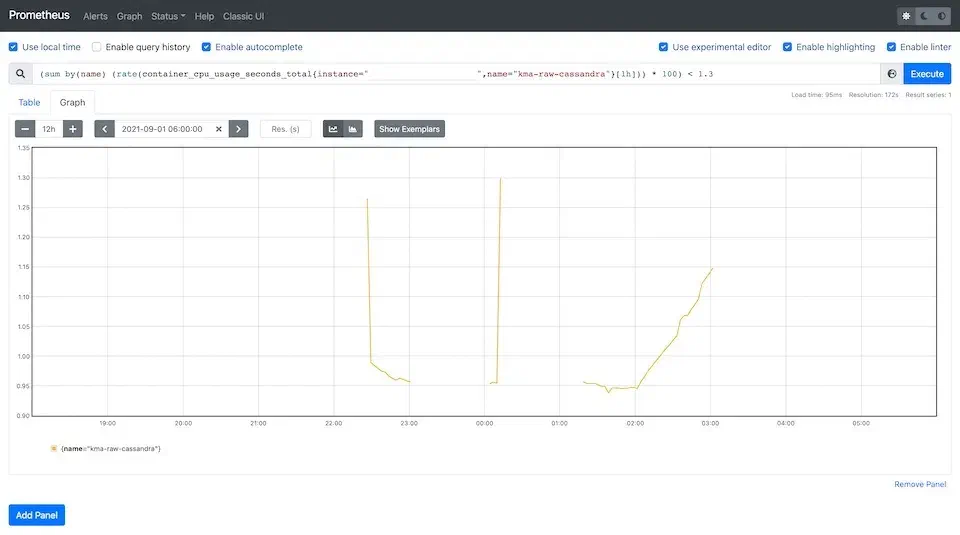
마지막으로 이 값이 임의의 값보다 낮은 경우 조건 < 1.3 을 추가해 주었습니다. 그러면 이렇게 컨테이너의 CPU 사용량 집계값이 1.3보다 작은 경우에만 값이 생기게 됩니다.
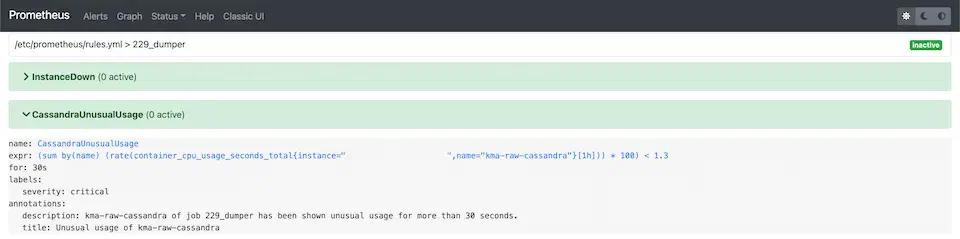
마지막으로는 이런 경우가 30초 이상 지속되면 알람이 가도록 규칙을 추가했습니다. 일반적으로는 오경보가 있을 수도 있고, 시스템에 잠깐 문제가 생기더라도 자가 치유를 하거나 너무 큰 문제가 아닐 수 있습니다. 또한 알림이 너무 잦은 경우 운영자에게 피로감을 주어 정말 중요한 알림일 때도 대수롭지 않게 여기게 될 수도 있습니다. 때문에 보통은 문제 상황이 5분 또는 수 분 이상 지속되는 경우에 알림을 보내도록 하고, Prometheus의 예시에도 5분, 10분 정도로 사용합니다56. 다만 저는 이 때는 알람을 받아보고 시스템과 상황을 더 잘 이해해야 할 필요도 있었고, DB는 중요한 컴포넌트이기도 해서 시간을 짧게 설정했습니다.
마무리
모니터링을 한다는 것은 내가 만든 것 또는 내가 운영하는 것이 제대로 동작하는지 책임감 있게 확인하는 중요한 수단입니다. 하지만 책임감있게 하루종일 콘솔 로그만 들어다보고 있을 수는 없으니까요. 그래서 Prometheus 시스템을 설치하고, 규칙을 추가해 알림을 자동화하며, 문제 발생 알림을 받았을 때 Grafana 대시보드를 보며 이상 징후를 확인할 수 있는 시스템을 구성했습니다. (이제 우리는 콘솔 로그를 잠시 끄고 🍚밥을 먹으러 갈 수 있습니다..!)
그리고 모니터링을 도입하는 입장에서 Prometheus는 그리 복잡하지 않지만 모니터링에 필수적인 기능은 모두 갖추고 있고, 컨테이너로 배포하기에도 잘 되어 있으며, 다양한 exporter도 많이 제공되는 만능 툴이라고 할 수 있을 것 같습니다. 조만간 제가 이 시스템을 설치, 구성했던 방법에 대해서도 정리해보려 합니다.
Prometheus. “What is Prometheus?” prometheus.io. https://prometheus.io/docs/introduction/overview/#what-is-prometheus (accessed Apr. 12, 2023). ↩︎
DavidZhang. “Pull or Push: How to Select Monitoring Systems?” http://www.alibabacloud.com. https://www.alibabacloud.com/blog/pull-or-push-how-to-select-monitoring-systems_599007 (accessed Apr. 15, 2023). ↩︎
X. Huang, J. Lee, Y.-W. Kwon, and C.-H. Lee, ‘CrowdQuake: A Networked System of Low-Cost Sensors for Earthquake Detection via Deep Learning’, in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 2020, pp. 3261–3271. ↩︎
신주용, 안재광, 이장수, and 권영우, ‘MEMS 가속도 센서 기반의 CrowdQuake 운영을 통한 지진 관측 데이터 분석’, 한국통신학회논문지, vol. 47, no. 1, pp. 206–213, 2022. ↩︎
jg.choi. “KHP 모니터링과 알림 - 2부.” tech.kakao.com. https://tech.kakao.com/2022/12/19/khp-monitoring-and-alarm-2nd/ (accessed Apr. 16, 2023). ↩︎
Prometheus. “Alerting rules.” prometheus.io. https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/#defining-alerting-rules (accessed Apr. 16, 2023). ↩︎
Outsider. “오픈소스 모니터링 시스템 Prometheus #1.” blog.outsider.ne.kr. https://blog.outsider.ne.kr/1254 (accessed Apr. 16, 2023). ↩︎
ShinChul Bang. “Prometheus란?” medium.com. https://medium.com/finda-tech/prometheus란-cf52c9a8785f (accessed Apr. 16, 2023). ↩︎
Comments