배경
지난 Rolling Update 실습을 통해 서비스 중단 없이 앱을 업데이트하는 방법을 알아보았습니다. 하지만 서비스를 운영하다 보면 업데이트만큼이나 중요한 것이 갑작스러운 트래픽 폭주에 대응하는 것입니다.
사람이 24시간 모니터링하며 서버를 수동으로 늘리는 것은 불가능에 가깝습니다. 이런 상황에서 사용 가능한 쿠버네티스의 HPA(Horizontal Pod Autoscaler)는 CPU나 메모리 부하를 실시간으로 감시하여, 부하가 높으면 Pod를 늘리고 부하가 사라지면 다시 줄여줍니다.
실습
web, was, db pod는 지난 Rolling Update 실습때와 동일하게 사용했습니다.
HPA 매니페스트
기본적으로는 was-deployment가 2개 실행되지만, CPU 사용량이 40%를 넘으면 확장을 시작하도록 HPA를 구성합니다. 최대 4개 Pod까지 확장 가능합니다.
1apiVersion: autoscaling/v2
2kind: HorizontalPodAutoscaler
3metadata:
4 name: was-deployment
5 namespace: lab2-hpa
6spec:
7 scaleTargetRef:
8 apiVersion: apps/v1
9 kind: Deployment
10 name: was-deployment
11 minReplicas: 2
12 maxReplicas: 4
13 metrics:
14 - type: Resource
15 resource:
16 name: cpu
17 target:
18 type: Utilization
19 averageUtilization: 40 # CPU 사용률이 40%를 넘으면 확장 시작
시나리오
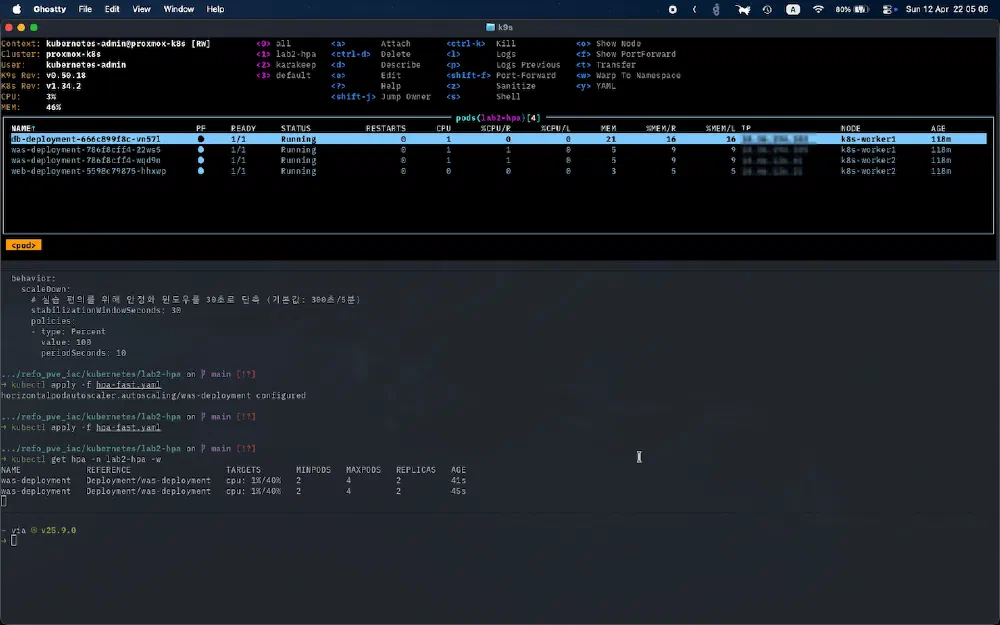
Step 1: 부하 발생 전 상태 확인
먼저 현재 HPA 상태를 확인합니다. 부하가 없으므로 사용량은 0%에 가깝고, 최소 개수인 2개의 Pod가 유지되는 것을 볼 수 있습니다.
1kubectl get hpa was-deployment -n lab2-hpa -w
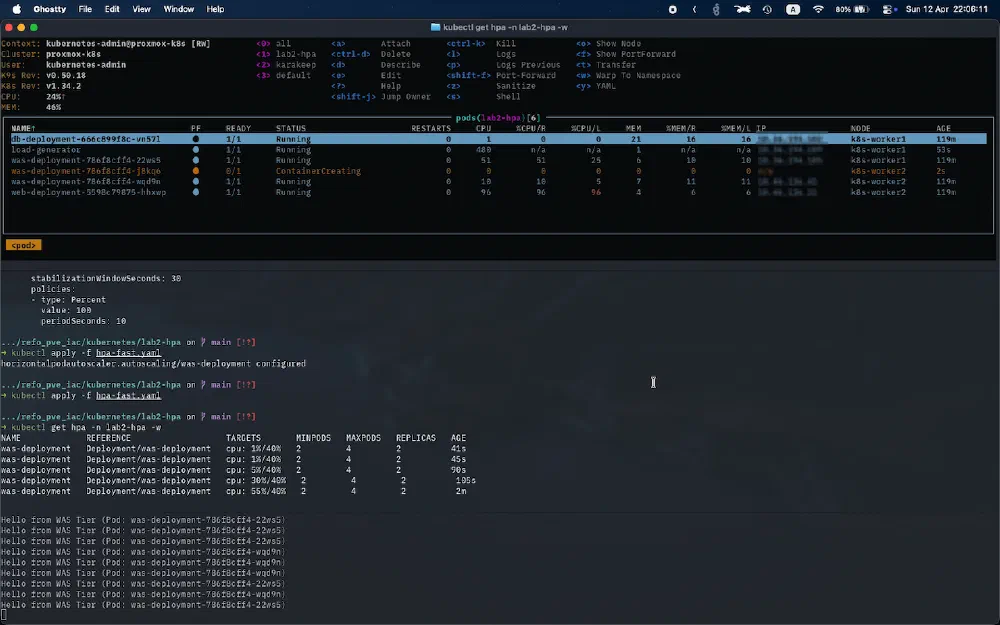
Step 2: CPU 부하 발생 시 자동 확장(Scale-out)
busybox를 이용해 무한 루프 요청을 보내 CPU 부하를 의도적으로 발생시켜보았습니다. 이후 CPU 사용률이 임계치(40%)를 넘어서면 Pod 개수가 2개에서 3개로 늘어나는 과정을 k9s나 터미널에서 확인할 수 있습니다.
1kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -n lab2-hpa -- /bin/sh -c "while true; do wget -q -O- http://web-service; done"
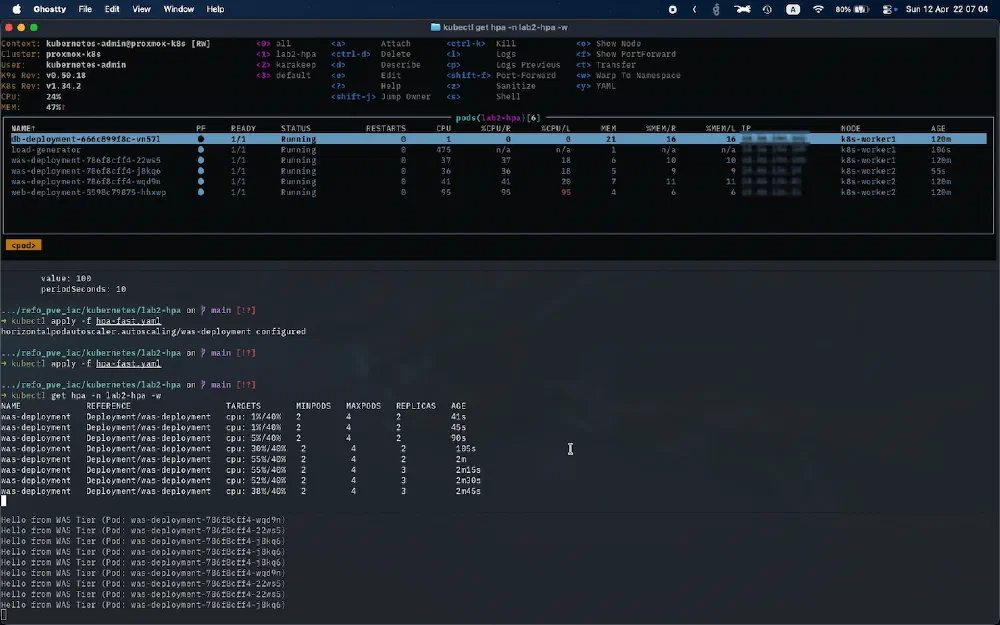
- 참고로, 테스트 시에는 부하가 증가할 때 Scale out 되는 것을 조금 빠르게 보고자 기준을 40%로 낮추긴 했는데, 만약 실제 배포할 때라면 이것보다는 조금 높은 기준을 사용할 것 같습니다.
- 일반적으로 생각했을 때는 CPU 사용률이 80-90% 수준이 되었을 때(부하가 있다고 생각될 때) Scale out을 하는 것이 맞지 않을까 하는 생각이 듭니다. 하지만 새로운 Pod가 생성되고 서비스가 준비될 때까지의 시간도 있기 때문에 80-90%가 넘을 때 Scale out을 하게 되면 새 Pod가 뜨는 동안 기존 Pod가 과부하로 죽어버릴 수 있습니다. 그래서 부하가 조금 더 낮을 때 미리 배포해두는 것이 전체 시스템 관점에서 조금 더 안정적으로 실행하는 전략일 수 있습니다.
Step 3: 부하 중단 및 축소(Scale-in)
그 다음으로는 부하를 발생시키던 busybox를 ctrl + c로 중지하여 Scale in이 되는 것을 확인해봅니다. 이때, 부하를 중단해도 Pod는 즉시 줄어들지 않습니다. 대신 시스템 안정성을 위해 일정 시간 대기 후 축소가 진행됩니다.
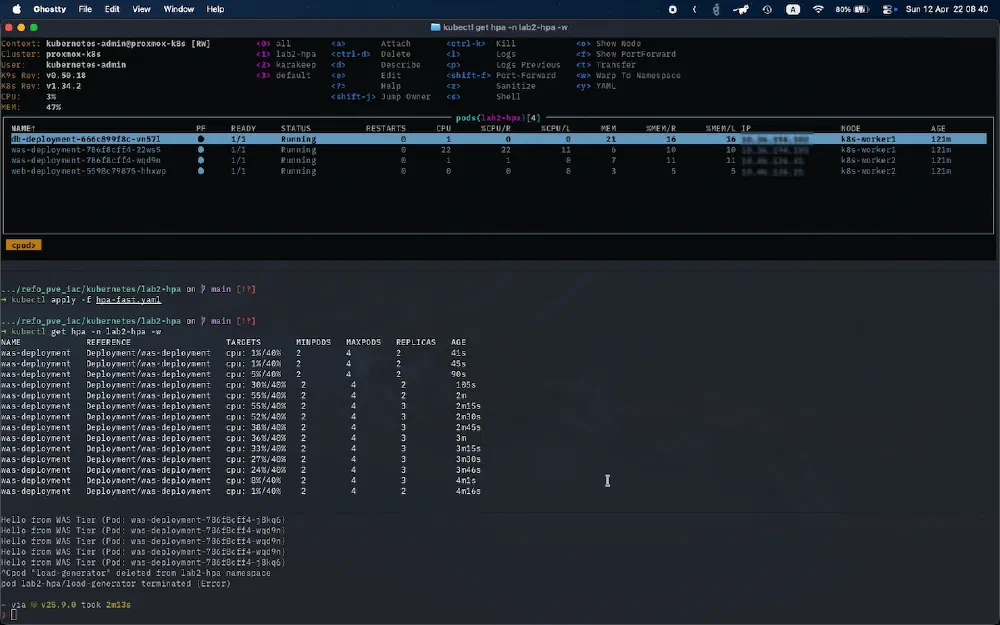
- 이 실습을 할 때는 축소도 조금 빠르게 보고자 시간을 30초로 줄였는데, 기본적으로는 사용률이 일시적으로 크게 움직이는 경우도 있기 때문에 이를 방지하기 위해 안정화 윈도우(Stabilization Window)라는 것을 사용합니다. 기본값은 5분입니다1.
추가 궁금증
- Deployment의
replicas, HPA의minReplicas/maxReplicas- Deployment의
replicas는 단순히 그 개수만큼 배포한다는 의미인 반면, HPA는 min/max 기준 내에서 사용량을 모니터링하며 동적으로 조정 - Deployment의
replicas값을 HPA의minReplicas값과 일치시켜 두면 재배포(Rollout) 시점에 Pod 개수가 의도치 않게 튀었다가 다시 조정되는 리소스 낭비를 막을 수 있어서 좋음
- Deployment의
마치며
그동안 토이 프로젝트를 할 때는 Docker Compose 정도만 사용해봐서, 트래픽에 따라 서버가 자동으로 늘어나는(Scale-out) 광경을 직접 구현해본 건 처음이라 신기했습니다. 실제 서비스 환경에서는 트래픽이 늘 유동적일 수밖에 없는데, HPA 같은 기술이 왜 필수적인지 체감할 수 있었습니다.
다만 실습을 하면서 서버가 늘어나는 것만큼이나 중요한 게 애플리케이션의 구조라는 생각도 들었습니다. WAS가 언제든 동적으로 늘어나고 줄어들어도 문제가 없도록 로직을 작성하는 것이 중요할 것 같고, 분산된 환경인 만큼 모니터링이나 Observability에도 더 신경을 써야할 것 같습니다. 이런 부분에 대해서도 조금 더 찾아보면 좋을 것 같습니다.
“Horizontal Pod Autoscaler,” Kubernetes Documentation, Accessed: Apr. 14, 2026. [Online]. Available: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#stabilization-window ↩︎
Comments